מנוע ההמלצות שלנו הוא עיקר גאוותנו והוא פיתוח עצמאי שלנו. שמו Movie Discovery וכשמו כן הוא: מסייע באיתור סרט או סרטים מתאימים למחקרים או הרצאות.
חוקרת או חוקר שמחפשים סרט המתאים להרצאה או פרזנטציה שהם רוצים להעביר, שוברים בדרך כלל את הראש בדרך למציאת הסרט המתאים. לרשותם עומד הידע הכללי שלהם או חבריהם על סרטים מוכרים או גוגל, שאינו מתמחה בהבנה ובהתאמה שבין נושא.
מאחר שכיום, מרצים רבים משלבים סרטים בהרצאותיהם ונוכח כוחו הברור של סרט ליצור המחשה ומעורבות רגשית של הצופים, הצורך במנוע המלצות כזה הופך אקוטי.
הוסיפו מן הצד השני את העובדה שכמות הסרטים האפשריים מדודה בעשרות אלפים (לספריות הגדולות יש 65,000 סרטים לצרכי אקדמיה ומחקר) ותגיעו בקלות למסקנה כי מנוע המלצות כזה הוא פשוט הכרחי.
זהו, בקיצור, סיפורו של מנוע ההמלצות מנקודת מבט של המשתמשים והמשתמשות. עוד על התפקוד שלו תוכלו לקרוא כאן.
הרשומה הזו עוסקת בטכנולוגיה שמאחורי ההמלצות, שמכונה למידה חישובית - Machine Learning. טכנולוגיה זו נמצאת כיום במרכז המחקר העולמי ומיטב המוחות מגויסים אליה מהאוניברסיטאות ומכוני המחקר. היא מסייעת למגוון אדיר של תחומים, החל מתרגום ולימוד שפה, דרך מניעת תאונות דרכים ועד ריפוי ואבחון מחלות.
נספר לכם כאן על הטכנולוגיה המרתקת הזו באופן הפשוט אך המדויק ביותר שנוכל.

מכונה לומדת מנסה לחקות את הלמידה האנושית. כולנו לומדים, כל הזמן, גם בלי לשבת בכיתה מול מורה ולשנן. הלימוד הזה הוא חידה עבור העולם המדעי: ילד יכול להיחשף למשל למאה חתולים שונים, אפורים או שחורים. פתאום, יום אחד, הוא יראה חתול לבן, שנפוץ פחות. רוב הסיכויים הם שהוא יצביע עליו ויגיד ״חתול.״ איך הוא יודע? הרי הוא לא ראה את החתול הזה או דומה לו מעולם?
הילד למד מהם המאפיינים של חתול והסיק מסקנה לגבי חתול שמעולם לא ראה כמותו. הוא ביצע אינדוקציה, למרות כמובן שלא ידע שכך קוראים לזה. אינדוקציה היא הסקה מן הפרט אל הכלל.
הפרט במקרה זה הוא למעשה האוסף המצטבר של הפרטים/חתולים שראה עד היום. כתוצאה מצפיה בעוד חתול/פרט ועוד חתול/פרט בנה הילד בנה בראשו כלל בלתי מפורש לגבי ״מהו חתול״ וכאשר פגש חתול לבן, יישם את הכלל שנבנה בהדרגה במוחו על החתול הזה. פשוט לכאורה, בסיסי ומובן מאליו, נכון?
ייתכן אפילו, שאם ננסה לנתח לאחור את ההסקה של אותו ילד, נצליח ליצור רשימת תכונות שיש לחתולים ואין לבעלי חיים הולכי על ארבע אחרים. אולי על פיהם הגיע הילד למסקנתו זו? רשימת תכונות זו נוצרה, לפי השערתנו הראשונית, בראשו של הילד בכל פעם שראה חתול.
למשל: נכון שגם כלבים הולכים על ארבע ויש להם שתי עיניים ושתי אזניים והם נמצאים בחברת בני אדם, אבל לכלבים אין עיניים זוהרות בחשיכה, הם פחות גמישים ומזנקים פחות על גדרות ועצים וגם לא נוטים לנחות בשלום כמעט מכל מצב.
המממ... משהו כאן לא נראה טוב: הרי הילד שראה חתול לבן לא בהכרח ביצע עליו תצפית מסודרת ולא ראה את עיניו של החתול הלבן בחשיכה וגם סביר שלא הזדמן לו לצפות בגמישותו של החתול או ביכולתו לנחות בשלום מגובה שני מטר.
הוא סתם ראה חתול לבן מתבטל בשמש, הצביע ואמר ״חתול.״
מה יש באותו חתול, שמספיק לילד מבט קצר בו כדי לדעת שהוא שייך לכלל שנוסח באופן בלתי מילולי במוחו של הילד? ואיך זה שהסקה כל כך מורכבת ולא חד משמעית לכאורה היא ברוב המקרים גם נכונה?
ועוד לא דברנו על היכולת של ילדים ובוגרים להסיק מסקנות לגבי דברים חמקמקים הרבה יתר מאשר הגדרה זואולוגית של חיית מחמד.
הדבר היום יומי הזה עבור בני האדם הוא האתגר הגדול ביותר של לימוד מכונה והאמת? המדע ועולם המחשבים עוד לא שם.
עד כאן פרופורציות + מהו בעצם לימוד.
אז מהי למידה חישובית?
ההגדרה הפשוטה והקצרה ביותר היא ״היכולת ללמוד מניסיון קודם.״ שימו לב: אין כאן ניסיון לטעון לקיומו של רגש, שמיוחס לשאפתנות של בינה מלאכותית, גם לא ליצירתיות, אלא ׳בסך הכל׳ ליכולת להסיק מסקנות.
רגע, הסקת מסקנות? הי, זה נשמע מוכר. ואכן, למידת מכונה קרובה יותר לססטיסטיקה ולכריית נתונים (Data Mining) מאשר לבינה מלאכותית. רגע, גם אם עולה בכם זיכרון כאוב של קורסי חובה בסטטיסטיקה, אל תברחו. יהיה כיף.
טום מיטשל מקרנגי מלון, חוקר בולט בתחום וראש ומיסד המחלקה ללימוד-מכונה באוניברסיטה היוקרתית, מסביר מהי המשמעות של מחשב שמבין מה שהוא קורא. יכולתו של מיטשל להסביר בפשטות היא יוצאת דופן ולכן נביא כאן את הרצאתו בדאבוס, בפורום הכלכלי העולמי:
במה זה שונה ממחשב שיודע לשחק איקס-עיגול?
מחשב שמשחק איקס-עיגול באפליקציות ומשחקי מחשב פשוטים וזמינים, מכיל בתוכו מראש את כל התרחישים האפשריים ובוחר את האופטימלי מביניהם על פי עקרון תרחיש->תגובה. מאחר שבמשחק יש כללים ברורים מאוד, אפשר להלעיט את המחשב בכל התרחישים האלה לפני שיתחיל במשחק הראשון וכך בדיוק נכתבת אפליקציית המשחק. נכון, הבחירה בתרחיש האופטימלי (הבחירה בצעד הבא, כלומר היכן לצייר את האיקס/עיגול הבא בתגובה למשחק האנושי) מבוססת על הסקה סטטיסטית, אבל הכללים שלה ברורים מאוד ותוכנתו עבורו מראש, כלומר אין כאן למידה אלא בחירה בצעד הבא במשחק כתוצאה של מימוש נוסחה.
לכן המחשב במקרה זה לא נחשב ״לומד.״
לעומת זאת, אם ניקח מחשב ונצליח ללמד אותו רק את הכללים של המשחק ואז נראה אותו מתקדם מהפסדים לנצחון תוך הפקת לקחים ממשחקים קודמים, נוכל לומר שהוא למד.
ניבוי
תוצאת הלמידה, שהיא פלט המחשב, שיכולה להיות המלצה על בית מלון או על ספר או על סרט או החלטה שתמונה מסוימת מראה שדה פרחים, אינה בטוחה לחלוטין. לכן בתחום למידת המכונה היא נקראת ניבוי (Prediction).
כבני אדם לומדים, לא נקרא לזה ניבוי. מקסימום נגיד ״נראה לי שהאיש בתמונה כועס״ ואולי נגיד ״האיש בתמונה מה זה כועס!״ בשני המקרים, בטרמינולוגיה של למידה חישובית, אנחנו מנבאים פלט ברמות שונות של וודאות.
נגיע מיד שוב לניבוי.
בסיס הלימוד: ניתוח מערכי נתונים ויצירת ניבוי
מחשב לומד, מנתח מערכי נתונים (Data Sets) ומבצע קיטלוג שלהם. רובנו מכירים קיטלוג כמשהו שמתמצה במילה אחת. אנחנו הרי מקטלגים בני אדם על פי ההקשר: מגעיל, נחמד, שמאלני, ימני, גבוה, נמוך וכן הלאה. חלק מההערכות ערכיות סוביקטיביות, חלק אחר עובדתי, אחרות יחסיות.
אלא שקיטלוג שמטרתו לימוד והפקת ערך מהנתונים הוא ענין מורכב יותר. לכל נתון יכולים להיות מספר קיטלוגים שונים, לכל אחד יכול להיות משקל אחר, כלומר עוצמה שונה של שיוך לאותו קיטלוג (נניח, גבוה אבל לא הרבה מעל לממוצע, שזוף אבל לא כהה וכו׳). לפעמים הם סותרים. לפעמים הקיטלוג הוא תוצאה של חיתוך ומפגש בין קיטלוגים שונים. לחיתוך הזה נגיע בהמשך.
חשוב לומר שקיטלוג אינו מהווה את תהליך הלימוד עדיין!
למה הדבר דומה? נניח שאתם מקבלים פרטים ביוגרפיים על אדם לצורך קבלה לעבודה. אתם מקבלים עליו נתונים רבים. ייתכן כי הניסיון הקודם שלכם בקבלת אנשים לעבודה הביא אתכם למסקנה (ניבוי), כי אנשים עם מערך תכונות כזה יהיו מוצלחים וכי האיש הזה חולק את אותן תכונות.
החלטתם לקבל אותו.
האם קבלתם אותו כי התנסיתם בעבודה עימו? לא וזה גם בלתי אפשרי, כשם שבלתי אפשרי לצפות בכל אלפי הסרטים ורק אז לקבל החלטה. רק ההיכרות והעבודה לצד אותו אדם יוצרת לימוד בפועל, כתוצאה מהניסיון המצטבר הממשי של עבודה עם האיש, שגם היא לימוד אגב.
אבל בכל זאת עשיתם כאן משהו מענין והוא ניסיון לנבא אם האדם מתאים לעבודה על בסיס קורות החיים שלו. הניבוי הזה הסתמך על:
* ניסיון קודם שלכם עם אנשים שהצליחו בעבודה, בהצלבה לתכונות שהיו להם.
* בניית מערך אידאלי של תכונות וכישורי האדם שאמור למלא את התפקיד (Wishlist של תכונות) והשוואה בין תכונותיו של אותו אדם כפי שהשתקפו בקורות החיים לרשימת התכונות האידאליות.
את שני הדברים האלה תנסה המערכת הלומדת לבצע: לקטלג את מערך הנתונים שמולה ועל בסיסה ליצור ניבוי.
קבלת אדם לעבודה על בסיס קורות החיים שלו (כלומר, אנליזה של מערכי הנתונים אודותיו) היא תמיד בחזקת נעלם. הצלחה בניבוי מעידה על יכולת הלמידה של המכונה.
כאשר מנהל או מנהלת משאבי אנוש מצליחה לנבא את הצלחתו של אדם בתפקיד, היא נחשבת מוצלחת. כאשר יעשה זאת מחשב במקומה בהצלחה, הוא ייחשב מכונה שלמדה בהצלחה.
מה המכונה למדה? לנתח ולנבא. אלו שני מרכיבי הלימוד הבסיסיים.
מה, יצרתי אצלכם צמרמורת? גם אתם מרגישים כי עוד מעט המחשב יחליף את כולנו, כמעט בכל מקצוע? מתחשק לכם להתפייט על כוחה של ההתרשמות האישית מהמרואיין, על המבט בעיניים, על תחושת הבטן? על האנרגיות באוויר? כל הדברים האנושיים האלו, שאין להם לדעתכם תחליף?
ייתכן מאוד שאתם צודקים. שמעתי במהלך חיי תובנות נחרצות לכאן ולכאן: חלק היללו את המרכיב האנושי בשיקולי קבלה לעבודה, עד כדי פסיקה שהדרך הטובה ביותר לקבל עובדים היא בהמלצות. אחרים סוגדים למבחנים הפורמליים, שהם הסבא והסבתא של המכונה הלומדת, בהיותם כלי כמותני אנליטי ליצירת ניבוי.
ובהעברה למנוע ההמלצות שלנו, אולי באמת אין תחליף להמלצה על סרט שבאה מחובב קולנוע או מאיש מדע, הטבול כולו בידע, לצד טעם טוב באסתטיקה קולנועית?
ייתכן מאוד שזה נכון, אבל מאחר שאדם כזה אינו תמיד בנמצא וגם אם הוא החבר שלנו או אנחנו עצמנו, אין הרבה סיכוי שהוא יכיר 65,000 סרטים בנושאים שונים ומשונים.
סוגי לימוד
- לימוד מונחה (Supervised Learning)
- לימוד בלתי מונחה (Unsupervised Learning)
- לימוד מחזק (Reinforcement Learning)
הסוג הראשון, הלימוד המונחה, הוא כזה בו אנחנו מזינים למכונה נתונים שכבר תויגו באופן מדויק. זהו הלימוד המהיר ביותר והוא גם מה שאנחנו עובדים איתו ב - Movie Discovery. צוותים שלמים עוברים סרט סרט ועל בסיס היכרותם עם הסרט, מתייגים אותו ומשייכים אותו לקטגוריות שונות. כלל היעילות של הלימוד המונחה הוא: ככל שבסיס הנתונים (המתויג כהלכה) רחב יותר, כך גוברת יכולתה של המכונה ללמוד. לימוד הוא יכולתה של המכונה לספק ניתוח מדויק של קלט שעוד לא נתקלה בו בעבר.
איך עושים זאת? מזינים הרבה ידע, בוחרים ׳לאמן׳ את המכונה (המונח המקובל לעיבוד המידע הגולמי נקרא Train) ואז מעמידים בפני המכונה אתגר ניתוח של נתון החדש לה, הפעם מבלי לקטלג אותו תחילה עבורה. המכונה הצליחה בקיטלוג משלה? - הצלחנו באימון. לא הצליחה? נחזור להאביס אותה בעוד נתונים.
לימוד בלתי מונחה כולל פרשנות מינימלית ביותר של הנתונים למכונה. צפיתם בהרצאתו של מיטשל למעלה? הוא מציג שם דוגמה לכתב הירוגליפי. אינכם יודעים מה משמעות כל אות, אבל אתם יודעים ש (1) מדובר באותיות וכן (2) בכתובת שהיא בעלת משמעות מסוימת. כך המכונה רואה אותיות שתציגו לה בלימוד בלתי מונחה. משימתה היא ללמוד את משמעות האותיות מתוך הקשרים מצטברים. למה הדבר דומה? לאדם שמהגר לארץ זרה ואינו לומד את שפתה באופן מסודר (לימוד בלתי מונחה). הוא נחשף לעוד ועוד גירויי שפה. לפעמים הם מלווים בתנועות ידיים או הבעות רגש. לפעמים הם מלווים באירועים, בסנקציות ובהקשר. למשל - האדם שאמר לי eser בקופה בסופרמרקט גם הושיט את היד לקבל כסף או כרטיס אשראי ולכן כנראה ש - eser הוא שם של מספר בשפה הזרה החדשה. בצעתי תהליך לימודי של מילה אחת באופן בלתי מונחה הודות להקשר מסייע ומצטבר, כלומר זה קרה יותר מפעם אחת ואולי בפעם הבאה זה קרה בהקשר מעט שונה, אבל כזה שתואם למשמעות שאני מנחש עבור המילה. נניח - כאשר מישהו רצה לקנות ממני מוצר בדוכן שלי בשוק והציע מחיר, הוא גם השמיע את הצליל eser. אז הסקתי ש - eser שייך לקטגוריית ה׳כסף׳ ורק נותר להמשיך וללמוד (בהתנסות נוספת) באיזה סכום מדובר. בזכות סיטואציות התשלום גם הסקתי/למדתי ש - eser הוא גם צליל ששייך לקטגוריית ה״מספרים״ כי כסף נמנה במספרים. אם רק יישלף מטבע של eser, המעגל ייסגר (בזכות הכתיבה הזו אני מבין לראשונה בחיי אני מבין כמה קשה היה לסבתא שלי ללמוד עברית).
אך שימו לב: ההפך אינו נכון, כלומר מספרים אינם נמנים בכסף. היחס בין שתי הקטגוריות (״כסף״ ו״מספרים״) הוא יחס היררכי -- ה׳מספרים׳ מכילים את ה׳כסף׳ אך לא ההפך. ידע זה על היררכיות בין הקטגוריות חייב להיות למכונה הלומדת מלכתחילה, אחרת היא לא תצליח לבצע לימוד בלתי מונחה. כי זאת יש לדעת: מכונה לא יכולה להיות טאבולה ראסה (לוח חלק). חלק מהמידע שהיא תקבל חייב גם לכלול מידע על היחסים בין מרכיבי הידע האלה כמו הנ״ל. יחסים אלה מכונים Data Relationship.
לימוד מחזק מעניק בדיעבד ציון לניבוי של המכונה. אם הציון גבוה, אז קיים יותר סיכוי שהמכונה תבחר בו בעתיד שוב וההפך. כאשר מדובר במשחק בו המכונה נצחה למשל, הרי לא נוכל לדבר על צעד אחד שהביא את הנצחון. לכן, כל צעד יקבל (בדיעבד כאמור) ציון יחסי לתרומתו לנצחון. משחקים רבים ייצרו בהדרגה אסטרטגיית מכונה.
הנתון בעל המשמעות הגדולה ביותר במה שנוגע ללמידה מחזקת הוא, שהציונים ניתנים רק אחרי שהתוצאה נודעת, כלומר בסוף המשימה (משחק, במקרה של הדוגמה שלנו). למידה מחזקת שואבת את השראתה מפסיכולוגיה התנהגותית או במה שידוע בביטוי ״המקל והגזר.״
נו, אבל איך המכונה לומדת בפועל?
השיטה הנחשבת לפשוטה ביותר ידועה כשכן הקרוב ביותר (Nearest Neighbour). נניח למשל שאני נותן למכונה לנתח סוגי מטבעות. במערך הנתונים יש לי נתונים על היקף מטבעות קיימים, משקלם, צבעם והחומר ממנו הם עשויים. אז כאשר יוצג למכונה מטבע אותו אינה מכירה (הוא אינו מקוטלג), היא תחפש את המטבע הקרוב ביותר אליו בכל מערכי הנתונים של המטבעות.
רגע, כל מערכי הנתונים של המטבעות? לא בהכרח. כדי לייעל את התהליך, נוכל להגדיר למכונה להתייחס רק למספר מסוים של מערכי נתונים. אותו מספר (המשתנה שלו) נקרא K. זכרו אותו, הוא יופיע בבחינה-:)
ישנן שיטות (אלגוריתמים) נוספות, הנושאים שמות אקזוטיים כמו ADA או QDA (נכון שהם ישר מעלים אסוציאציה של קוקטייל על אי טרופי?).
האלגוריתם שאנחנו עובדים איתו (תודה ששאלתם) נקרא Naive Bayes. הוא הוכנס לידיעה הקהילה המדעית העוסקת באחזור טקסט בשנות ה - 60' ונחשב לפופולרי עד היום. יתרונו ביכולת לקטלג (classify) טקסטים, שזה אהם, בדיוק מה שאנחנו עושים. האלגוריתם מבצע הערכות הסתברותיות שמתבססות על התיאורמה של Bayes. תיאורמה זו מנסה לשער מהי ההסתברות של היווצרות אירוע מסוים (במקרה שלנו, 'אירוע' הוא קיטלוג) על בסיס מספר תנאים שדרושים כדי שאותו אירוע יתקיים. למשל - קיטלוג טקסט כעוסק בהפרעות אישיות ('אירוע קיטלוג') יתרחש רק אם יתקיימו מספר תנאים לכך. למשל, שהטקסט יעסוק בהפרעות אישיות. שימו לב! מילוי התנאי אינו מחייב הכרח את קיומה בטקסט של מילת או ביטוי מפתח כמו "הפרעת אישיות." אם זה היה המצב, אז היינו מסתפקים פשוט בחילוץ מילות מפתח. כבודן במקומן מונח, אבל מילות מפתח נחשבות לדבר מתוחכם פחות. אנחנו שואפים ליצור מכונה שתבין מתוך ההקשר שמדובר בטקסט העוסק בהפרעות אישיות, או במילים אחרות, שתהיה אדם אמפתי וקשוב (מה כבר בקשנו?).
אמנם ישנה נטיה כיום להשתמש באלגוריתמם החדש יותר Support Vector Machine, אבל יתרונו של Bayes בכל זאת הוא ביכולת להגדיל את האמינות ככל שהמדגם גדל, מה שמתאים לצרכים שלנו בדיוק (בינגו).
שימושי הלימוד
מה יכולה המכונה ללמוד ובמה היא יכולה לשרת את בני האדם, כלומר, לפני שהיא תהיה אינטליגנטית ותכריח אותנו לשרת אותה?
- איתור שפה: אתם כותבים באיו שפה שנוח לכם והמערכת מנסה לנחש, על בסיס ידע מוקדם שיש לה בשפה, באיו שפה אתם כותבים. גוגל טרנסלייט עושה בזה שימוש נרחב ומאפשר לכם לדלג על שלב בחירת שפת הקלט, כלומר השפה ממנה אם רוצים לתרגם. אולי זה נראה טריוויאלי כשחושבים על איתור עברית, שפה קטנה עם מאפיינים ייחודיים, אבל בהינתן שישנן מילים רבות שנכתבות באותו אופן בשפות שונות ועם אותיות לטיניות, המערכת באמת נדרשת ללמוד.
- קיטלוג מוצרים: זהו השימוש המסחרי הנרחב ביותר של בינה מלאכותית. זהו גם השימוש שאנחנו עושים ביכולות הלמידה, כאשר במקרה שלנו, אנחנו מחליפים את המילה מותר בטקסט אקדמי או ספרותי. קיטלוג טקסט, של תיאור מוצר או מחקר או סרט הוא מבחינת המכונה אוסף של מילים היוצרות משמעות כתוצאה מהשמתן יחד על פי כללי תחביר. המשמעות של הטקסט היא שלם הגדול מסכום חלקיו, כלומר היא לא יכולה לנבוע רק מחיבור המשמעוויות המצטברות של המילים (אחת ועוד אחת ועוד אחת). חייבת להיות משמעות הנגזרת, שמאפשרת למכונה לקבוע "זהו טקסט על התרבות צבי ים בסביבה בעלת אקלים משתנה בחצי הכדור הצפוני."
- ניתוח רגשות: האם הטקסט נכתב עם אוריינטיה חיובית או שלילית? אנחנו בקושי עושים בזה שימוש כיום, מכיוון שהכיוון שלנו הוא טקסטים אקדמיים ולא אכפת לנו אם המאמר הוא ביקורתי או אוהד, כל זמן שנספק המלצה על סרט באותו נושא. לעומת זאת, ניתוח רגשות חשוב מאוד לפרסומאים, פוליטיקאים, מנהלי שיווק ועוד, כדי לדעת מה אנשים חושבים על מה שאלו מנסים לקדם.
חייבים להודות שהביטוי "ניתוח רגשות" (Sentiment Analysis) נשמע קצת כמו דבר והיפוכו. לכאורה, האם לא נכון לשפוט רגשות על פי רגש? מה ענין ה"ניתוח" לכאן? גם כאן, כמו שתרחיש הקבלה לעבודה שתואר קודם, אין תשובה חד משמעית. זאת משום שישנם תמיד גם כאלו שטוענים שהמוח שלנו, לו אנחנו מייחסים רוחניות, הוא לא יותר מאוסף של חישובים המבוססים על תגובות עצביות חשמליות וכימיות, מה שידוע כרדוקציוניזם.
מדידת הלמידה
למידה היא חסרת ערך אם אין דרך למדוד את הצלחתה. אצל בני אדם, גורם המוטיבציה הוא מרכיב מרכזי בהצלחה הלימוד. בלמידה חישובית לעומת זאת, אין מרכיב של מוטיביציה של המכונה ולכן אם המכונה נכשלה, סימן שהאימון היה לא נכון או לא מספק.
קיימות מספר שיטות מדידת הצלחה מקובלות בתחום הלמידה החישובית:
דיוק: המינוח המקובל הוא Accuracy. משתמשים במדידה הזו עבור מערכים בינאריים, כלומר כאלו שהתשובה עליהם היא ״נכון״ או ״לא נכון״ (0 או 1). במדד הדיוק מודדים את מספר התשובות הנכונות חלקי התשובות הלא נכונות שנתנה המכונה. שימו לב: תשובה נכונה יכולה כמובן להיות ״לא״ (True Negative). קיימת ביקורת על השיטה, מאחר שהיא עלולה להניב חיזוי הצלחה גבוה יותר מהתוצאה האפשרית בפועל, מה שידוע כפרדוקס הדיוק. לכן מומלץ יותר להשתמש בשיטה הבאה:
דייקנות והיזכרות - Precision and Recall: המונח המקובל לדיקנות הוא Precision. הבחירה במילה הזו לעומת Accuracy שבסעיף הקודם היא שרירותית, אולם מבחינת המתודלוגיה, מדובר בשיטה טובה יותר. דייקנות בודקת אך ורק את הניבויים הנכונים שהם גם רלוונטיים. אמנם גם בסעיף הקודם, דיוק, המערכת מדדה ניבוי נכון, אלא ששם גם היה הרבה ניבוי לא רלוונטי ללימוד. ניבוי לא רלוונטי הוא תשובה שלילית שנתנה המכונה ושהתבררה כנכונה (True Negative). ובכן, מתברר שתשובות שליליות, גם אם הן נכונות, אינן מועילות לבדיקת תהליך הלימוד. לכן, התייחסות אך ורק לפסיקות החיוביות הנכונות (True Positive) היא רלוונטית.
ולמי ששואל למה הכוונה בשלילי או חיובי נזכיר שמדובר במערכות בינאריות, כלומר ב - 0 או 1.
המילה השניה במושג, היזכרות (Recall), היא תמונת המראה של דייקנות (Precision), כלמר היא עונה על השאלה ״באופן יחסי, כמה פעמים קרה המכונה נתנה תשובה נכונה על התוצאות הרלוונטיות (חיוביות).״
טבלת בלבול - Confusion Matrix: כלי הבודק באופן ויזואלי את כמות הניבויים הנכונים והשגויים. למשל, במערכת למידה חישובית שמלמדים אותה להעריך תוכן של תמונות, המערכת תישאל ״האם זה חתול?״ אם המערכת תענה שזה חתול וזה אכן חתול, התגובה תיספר כ - True Positive ותוכנס בטבלה למשבצת המתאימה. אם המערכת תסווג את התמונה ככלב והתברר שהמערכת טעתה, המשמעות היא False Positive. אם המערכת זיהתה שלא מדובר בחתול ואכן לא מדובר בחתול, זהו True Negative.
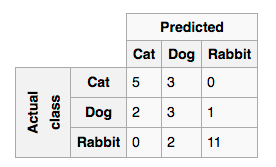
יש לטבלה הנראית בתמונה כוח ויזואלי לפשט דברים: על השאלה ״האם מדובר בחתול,״ המערכת אבחנה 5 פעמים שמדובר בחתול וצדקה (True Psitive). המערכת העריכה פעמיים שמדובר בחתול וטעתה (False Positive). המערכת לא העריכה מעולם שארנבת היא חתול וצדקה (True Nagative).
וכך הלאה לגבי שאר בעלי החיים: על השאלה ,האם זהו כלב״ התשובה היתה נכונה בשלושה מקרים ושגויה בשלושה מקרים, בהם היה מדובר בפועל בחתול ועוד פעמיים בהם היה מדובר בפועל בארנבת וכן הלאה. בסופו של דבר, נראה שהמערכת יודעת לנבא בצורה הטובה ביותר מתי תיראה בתמונה ארנבת, שכן ההערכה היתה נכונה 11 פעמים (המספר הגבוה ביותר) ורק פעם אחת, מה שהמערכת חזתה כארנבת, התברר ככלב.
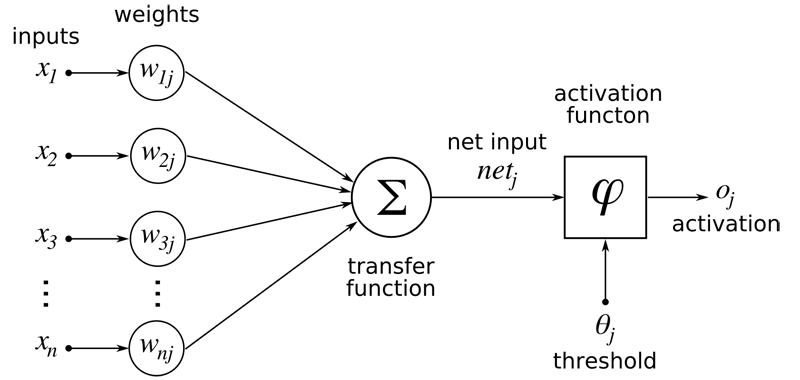
רשתות ניורונים
זהו, חיכיתם חצי שעה לביטוי האופנתי הזה והנה הוא בא. מונח זה - רשתות נוירונים מלאכותיות (ANN), מושפע מחקר מערכות העצבים בבעלי חיים ובראשם בני האדם. מטרתו לתאר מצב בו מעבדי מידע שונים פועלים במקביל (ולא בזה אחר זה) וכל אחד מעביר מידע מעובד למספר מעבדים אחרים בו זמנית על פי ההקשר ולא באופן קבוע. אחד העקרונות החשובים ביותר ברשתות נוירונים הוא הבו זמניות של התקשורת. מתכנן המערכת מחליט לאילו גירויים (קלט) היא תגיב ובאיזה אופן. כל גירוי מקבל מספר המייצג את משקלו ועוצמתו של הגירוי ומועבר למעבד/נוירון אחר כך חוזר התהליך מספר פעמים עד שהמערכת למדה (כלומר, הגיעה לרמת וודאות שהוגדרה מראש על ידי המתכנן) ואז היא מוציאה פלט, שהוא הניבוי שלה. מעבד במערכת יוכל לקבל שוב ושוב את אותו גירוי ובכל פעם ייתן לו משקל אחר. לא מדובר בענין שרירותי. השוני הוא יכולת ההסתגלות של המערכת והוא עמוד השדרה של הלימוד בפועל. קיומה של יכולת ההסתגלות הזו הוא תנאי בסיס להגדרתה של רשת נוירונים, לצד תכונת הבו זמניות שהגדרנו קודם.
בשנים האחרונות נעשה שימוש גובר ברשתות נוריונים עמוקות, בהן יש מספר שכבות של רשתות נוירונים. כל שכבה מתנהלת עצמאית ומתקשרת עם שכבות אחרות בצמתים ידועים מראש ולא מכל מעבד ומעבד. גוגל עושה שימוש רב בלמידה עמוקה (עוד ביטוי עבור רשתות נוריונים רב שכבתיות) כדי לבצע משימות מורכבות כמו זיהוי קולי ותרגום. בזכות רשתות כאלה, גוגל שפרה את הזיהוי הקולי שלה מ - 23% טעות ב - 2013 ל - 8% בלבד ב - 2015.
שאלות?