תמלול של תוכן אודיו וההבנה של מה שנאמר בו הם אתגר אדיר, הן לאנשי ארכיון והן לעיתונאים, סטודנטים ויוצרי סרטים. צליל מוקלט הוא מבחינת המחשב אוסף של ביטים חסרי משמעות. טוב, לא לגמרי. זיהוי קולי כבר קיים לא מעט שנים, אלא שהוא מוגבל מאוד. כל מי שניסה לבקש מהעוזר האישי של אפל, גוגל, אמאזון או מיקרוסופט לבצע פעולה, יודע שמדובר במשימה עם הרבה חורים. המכונה תתפקד טוב יותר כאשר תלמד לזהות את קולכם, היא מתקשה לבודד רעשי רקע, צריכה שתדברו ברור ופעמים רבות היא פשוט לא מבינה מה רציתם, אלא אם הצגתם שאלה או משימה בצורה ברורה וחד משמעית, מבחינת מבנה המשפט.
כשמשווים זאת ליכולת האנושית, בה אנשים מבינים אותנו גם בנסיבות רועשות וכאשר אנחנו אומרים מילים לא ברורות כמו ״זה״ ״מה שמו״ ושאר ביטויים עמומים, המערכת הממוחשבת נראית רע מאוד.
אבל יש התפתחויות. כל הזמן. נספר לכם כאן על פרויקט ציבורי ואקדמי מענין בתחום. חוסר המסחריות שלו אילץ את המפתחים לבצע אינטגרציה של שורת כלים בקוד פתוח, מה שהופך אותו למרתק אף יותר. רשות הדיבור לפרויקט HiPSTAS.
HiPSTAS
סטיב מקלאפלין, דוקטורנט למדעי המידע באוניברסיטת טקסט באוסטין יצר ערכת תיוג אודיו, שמאפשרת לאנשי ארכיון שאינם תכנתים ללמד מכונה לבצע זיהוי קולי של קטעים ולתמלל אותם.
האתגר הוא מרובה שכבות: צריך לבנות מערכת שתעבד את האודיו. יש ליצור דרכים שיאפשרו לנו ללמד את המכונה ולבסוף יש לקחת את הידע של המכונה וליישם אותו על האודיו המנותח.
בין כלי ניתוח האודיו שמקלאפלין עשה בהם שימוש נמצאים FFmpeg המפורסם והוותיק וכן Librosa ו - Aubio. מצאתי את האחרון מענין במיוחד, שכן הוא יודע לאתר ולסמן גבהי צליל וכן שינויים בריתמוס ובמקצב.
הסבר קצר
עיבוד אודיו מוכר לרובנו, גם אם איננו יודעים לקרוא לו בשם. הוא נעשה ביוטיוב כל הזמן. כאשר אתם מעלים וידאו ליוטיוב, יוטיוב מבצעת ניתוח של הקובץ ו״מקשיבה״ לו. אחר כך היא משווה את מרכיבי האודיו למה שיש אצלה כבר בקטלוג ואם מצאה התאמה בין האודיו שהעליתם לבין זה ש אודיו שקיים בקטלוג שלה והוא שייך לאמן, היא תסמן לכם שהחומר שלכם מוגן בזכויות יוצרים.
עד כאן, זהו זיהוי ״טיפש״, מכיוון שהוא כולל קיטלוג של מרכיבי צליל של שיר ידוע ומוכר, שהוקלט באופן מקצועי ויש לו מאפיינים חדים וברורים. המערכת של יוטיוב ענקית ומהירה ויש לה יכולת בידוד מסוימת מרעשי רקע: למשל, היא תדע לאבחן את השיר גם אם הוא ערוך (חתוך) או שהוא נמצא רק ברקע של פס הקול של הוידאו שהעליתם, יחד עם קולות ילדים צועקים במסיבה למשל. אבל בסופו של דבר, זהו זיהוי של ביט מול ביט (השיר המקורי מול פס הקול של הוידאו שהעליתם), לכן אני מכנה אותו כאן זיהוי ״טיפש״.
לימוד המכונה
זהו החלק המרתק והמאתגר ביותר. הוא גם מחייב אותנו להיות מודעים למגבלות המכונה. על האופן בו מחשב לומד, הדרך בה הוא משתפר כתוצאה ממשוב ומה זה בכלל לימוד הרחבתי במאמר אחר כאן בבלוג.
ככלל, עלינו להגדיר את מה שנרצה לזהות ולבודד אותו. אי אפשר סתם כך לזרוק ערבוביה של קולות ולבקש מהמחשב לזהות אותם. עלינו לבודד כל דובר ולאמן את המכונה איתו. או במילים אחרות: אל תנסו לתמלל שיחה מרובת משתתפים בפאב עם מוסיקה רועשת, בה הם נכנסים אחד לדברי השני. אין סיכוי. זה אנושי מדי.
המשימה מתחילה באופן ידני, בשלב בו אנחנו מספרים למכונה מה היא שומעת (כאמור, בעזרת כלי ניתוח האודיו שהוזכר פיסקה למעלה).
שלב זה מכונה גם Labeling.
עלינו לבודד קטעים בני שניה אחת ולתת לכל אחד מהם תגית. התגיות חייבות להיות סגורות וקבועות (תזאורוס). כלומר, אם החלטתם שצליל מסוים מסוים שייך למשה, קראו לו כך בכל המופעים שלו ולא נניח מושה, משה, מ. וכו׳.
ניתן לבצע תיוג של האודיו באמצעות האפליקציה שמקלאפלין פיתח. היא ניתנת להתקנה ב - CLI, יש הסבר מפורט על הצעדים הנחוצים להתקנתה.
יש צורך באזור 500-1000 דגימות כדי ללמד את המכונה באופן יעיל דגימת קול אחת.
אני יודע, זה נשמע הרבה, אבל סביר לחלוטין בעיני. בכלל, אני חסיד גדול של Supervised Learning. כל מי שאני מספר לו על בינה מלאכותית והוא חיצוני לתחום מתאכזב לשמוע שצריך להשקיע זמן ואנרגיה כדי ללמד את המכונה. בדימוי, הרובוט יודע לעשות הכל לבד, כולל ללמד את עצמו. ובכן, זה רק בדימוי.
ביצוע בפועל
עלינו לבחור בקפדנות את מה שנרצה לנתח. כאמור, אי אפשר לנתח הכל. מקלאפלין מכנה בידוד והתמקדות כזו speaker of interest. כדי להגביר את הדיוק, הוא מציע לעבוד גם בשיטה הופכית מענינת על ידי ביטול הדגימה של סאונד שאינו מענין אותנו. זאת ניתן לעשות באמצעות הכלי הבא.
לאחר מכן נאחד סגמנטים של שניה אחת לחבילות של מספר שניות ונבודד תנועות (vowels) מעיצורים (consonants).
חשוב לזכור שכל דגימה מחייבת יצירת מודל לימוד נפרד, אותה נשמור כפייתון pickle ואותה נריץ.
כל תוצרי העיבוד (classifier) צריכים לעבור נירמול וניקוי על ידי קביעת סף (threshold).
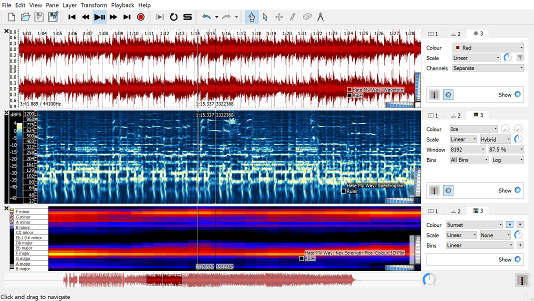
לבסוף, המגע האנושי! יש להטעין את הנתונים המנותחים, שכרגע הם ב - CSV, לתוך כלי המבצע ויזואליזציה של הסאונד המנותח. הוא מאפשר לנו לצפות באופן גרפי בסאונד המנותחת ולבצע תיקונים של התגיות.
בהצלחה לכולנו.